Have you ever wondered how a simple program that just yesterday helped you calculate taxes can suddenly compose jazz, create epic symphonies, or mimic the raspy vocals of your favorite rock star? It may feel like magic, but behind this “Digital Mozart” lies not a magic wand, but an incredibly sophisticated mathematical process.
From the First “Beep” to Neural Networks
It all began in 1951 when Alan Turing, the father of modern computing, programmed a massive machine to play the British national anthem. Back then, it sounded like a series of mechanical drones. Today, AI models generate tracks indistinguishable from professional studio recordings. We have evolved from simple “if-then” rules to complex neural networks that perceive and adapt to musical context.
How a Computer “Hears” Music
While humans experience music as emotion and vibration, AI treats it as a high-dimensional mathematical space. To compose, an algorithm must first learn to “perceive” sound. This generally happens through two primary methods:
- The Symbolic Domain (MIDI): Think of this as reading a digital score. The AI processes commands—”press key C4 with a velocity of 80 for 2 seconds.” This is ideal for maintaining structural integrity and melody.
- The Audio Domain (Raw Audio): The AI analyzes the actual sound wave. A prominent method involves spectrograms—visual maps of sound where frequencies are rendered as visual data. Models like Riffusion essentially “paint” music and then convert these images back into audio signals.
Insight: Lower layers of a neural network recognize basic elements like timbre or individual notes, while higher layers grasp complex patterns like rhythmic structures or the harmonic progressions of a pop hit.
Emotional Intelligence: How Machines Interpret “Mood”
How does an algorithm made of ones and zeros understand that a song should feel “nostalgic”? This is where Large Language Models (LLMs) and Joint Embeddings come into play.
When you enter a prompt like “energetic track for running,” the AI performs a semantic analysis. Using technologies like MuLan, words and sounds are mapped into a shared mathematical space.
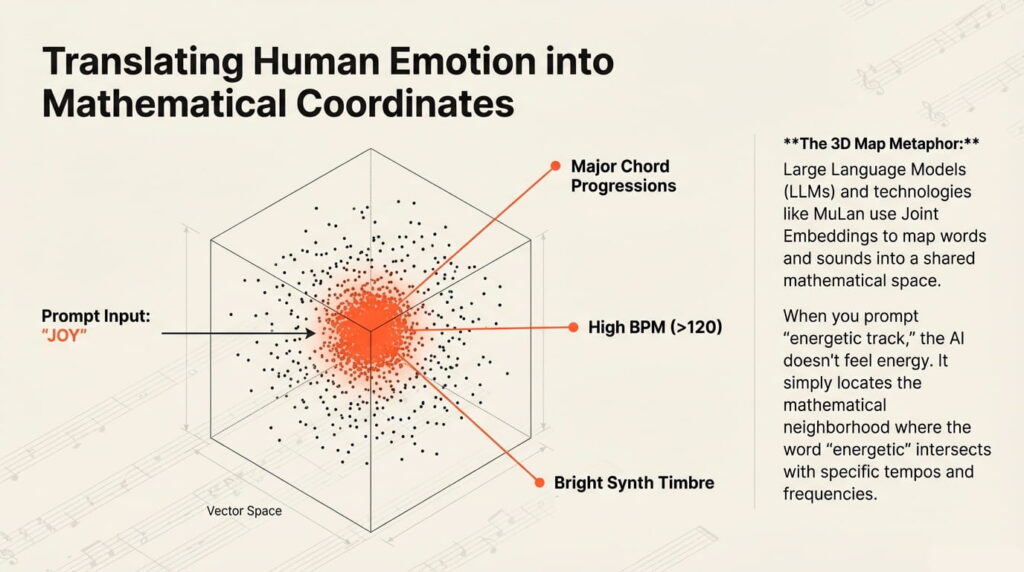
The 3D Map Metaphor: Imagine a vast digital landscape. In one specific coordinate, you find the word “joy.” In that same vicinity “live” major chords, high BPMs, and bright synthesizer timbres. When you provide a text prompt, the AI simply identifies the musical parameters that are mathematically closest to your words.
The Architecture of Creativity: Maintaining Coherence
To prevent a song from collapsing into chaos after a minute, AI utilizes two critical tools: Transformers and Hierarchical Modeling.
- The Attention Mechanism This is what provides the AI with “long-term memory.” Unlike a linear tape recorder, Transformers act like architects viewing an entire blueprint at once. The attention mechanism allows the model to “look back” at any moment to ensure the current chorus harmonizes with the intro generated minutes prior.
- The Digital Framework: Hierarchical Modeling This acts as the “executive director.” Rather than predicting every millisecond of sound at once, the system operates in layers:
- Semantic Level: Plans the narrative, tempo, and structure (verse-chorus).
- Acoustic Level: Creates the “rough sketches” of melody and rhythm.
- Detailing Level: Adds fine nuances—vocal vibrations, instrument textures, and atmospheric depth.
The Magic of Words: From Text to Vocal Performance
Generating songs with lyrics presents a unique challenge: making word stresses natural and avoiding the robotic “text-to-speech” feel of the 1990s.
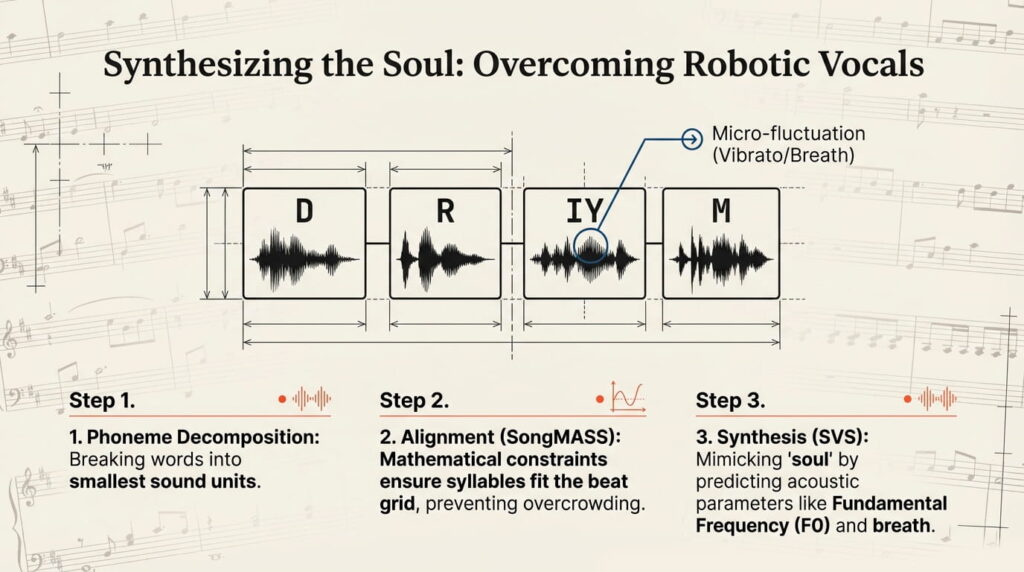
- Phoneme Decomposition: The AI breaks text into the smallest phonetic units.
- Alignment: Models like SongMASS use mathematical constraints to ensure each syllable fits precisely onto a note, preventing the “crowded” sound of mismatched lyrics and tempo.
- Singing Voice Synthesis (SVS): The network predicts acoustic parameters like fundamental frequency (F0) and timbre, mimicking human breath and emotional micro-fluctuations.
Digital Metamorphosis: Mimicking the Greats
AI can now deconstruct an artist’s creative DNA. Whether it’s a “new” Nirvana track or Frank Sinatra “covering” modern hits, the technology relies on:
- Voice Cloning & Latent Spaces: Using Variational Autoencoders (VAE), AI compresses thousands of hours of an artist’s recordings into a “latent space”—a mathematical model of their voice, capturing everything from unique timbres to specific pronunciations.
- The Vibe (Style Transfer): Beyond the voice, AI mimics the “soul” of a genre. It analyzes the harmonic preferences of The Beatles or the drum patterns of modern techno. Using Embeddings, the system doesn’t just add a guitar; it selects the specific distortion and frequencies popular in a given era.
Platforms like Grimes’ Elf.Tech (currently inactive) pioneered a new era where an artist’s voice is a licensed algorithm rather than just a physical trait.
The Legal Chaos: Who Owns the Magic?
The world of AI music is currently a “Wild West.” When an algorithm creates a hit, we face a legal triangle: Who is the author? The developer, the user who wrote the prompt, or the thousands of artists whose data trained the model?
- The Training Data Conflict: Lawsuits from Universal Music Group and Warner against companies like Suno or Udio argue that AI training is industrial-scale digital piracy—using copyrighted recordings without consent or compensation.
- The Copyright Gap: Currently, in many jurisdictions (including the US), works created solely by a machine without “significant human input” cannot be copyrighted. This creates a vacuum where AI-generated tracks belong to everyone and no one.
- Professional Erosion: For many, AI is not a “helper” but a “displacement machine.” Why hire a composer for a commercial jingle when an AI can do it for free in seconds? This threatens the livelihood of the “middle-class” musician.
Conclusion: A Symphony of Progress or a Requiem for Talent?
We stand at a crossroads in cultural history, facing two irreconcilable truths.
On one hand, we are witnessing a profound democratization of creativity. The barriers of expensive education and studio time have crumbled. AI gives a voice to those with brilliant ideas but no technical training. It is an explosion of new genres and accessibility.
On the other hand, we are seeing the devaluation of human labor. Thousands of hours of practice and years of studying harmony now compete with a single button press. Music risks becoming “acoustic fast food”—perfect in form but hollow inside, lacking the genuine human pain, experience, and sincerity that no algorithm can calculate.
AI will not settle the debate on what “true art” is. It will only force us, the listeners, to choose: do we want to consume a flawless mathematical sequence, or are we still searching for the living person behind the sound—flaws, soul, and all? The Digital Mozart has arrived; whether we want to buy a ticket to the performance remains to be seen.
P.S. Discover Laurie Spiegel: A Pioneer of Electronic Music — how she began bridging the gap between human emotion and algorithmic sound decades ago.
Rate this post along with 0 others